The University of Michigan operated a Kendall Square Research KSR-1 parallel processor with 32 processors until its decommissioning in 1995. Although the memory is physically distributed, as with the BBN Butterfly, it is logically shared due to the unique architecture of the system. The message-passing version of the TPHOT code was implemented on the KSR-1, utilizing ``pthreads'' which are not like macrotasking on the Cray YMP. Table 5.3 tabulates the simulation times for our implementation of TPHOT on the KSR-1. Since one ``pthread'' corresponds to one processor for our timing runs, the table gives the run times in terms of ``processors''. In almost all cases, the Monte Carlo results are identical between the BBN and KSR-1 runs, with some exceptions that are thought to be due to the fact that decisions made on floating point arithmetic are sensitive to the order in which the sums are accumulated. In addition to the observed times, table 5.3 includes the corresponding speedups computed using equation (5.1) and using the single processor case for each workload as the reference serial run.
Using the same approach as with the BBN, the constants a and b needed in equation (5.11) for the KSR-1 were obtained using the single processor runs for W=0.01, 0.10 and 1.0:
| (122) |
| (123) |
These values were then used to predict the serial execution time ![]() as a
function of workload W. These are given in table 5.4, along with the
corresponding
serial function, f. As with the BBN, the workload W=10.0 was not simulated for
N=1; only the predicted values are shown. For the KSR-1, the value of
as a
function of workload W. These are given in table 5.4, along with the
corresponding
serial function, f. As with the BBN, the workload W=10.0 was not simulated for
N=1; only the predicted values are shown. For the KSR-1, the value of ![]() was
found to be approximately 0.002, somewhat independent of workload W. The observed
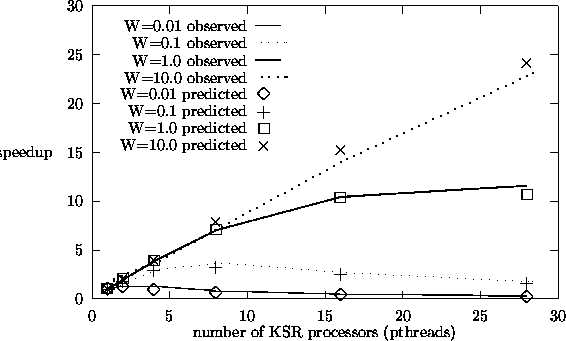
and predicted speedup plots for the KSR-1 are shown in figure 5.4. The speedup curves of
the KSR-1 show similar characteristics as that of the BBN Butterfly parallel processor,
i.e., as the workload increases, almost linear speedup is observed.
was
found to be approximately 0.002, somewhat independent of workload W. The observed
and predicted speedup plots for the KSR-1 are shown in figure 5.4. The speedup curves of
the KSR-1 show similar characteristics as that of the BBN Butterfly parallel processor,
i.e., as the workload increases, almost linear speedup is observed.
| 1|cNumber | 1|c | 1c Workload (W) | 1c | 1c| |
| 1|cof | 1|c0.01 | 1|c 0.1 | 1|c1.0 | 1|c|10.0 |
| 1|cprocessors | 1|ctime |
1|c time |
1|ctime |
1|c|time |
| 1|c | 1|c(sec) |
1|c (sec) |
1|c(sec) |
1|c|(sec) |
| 1 | 3.52 |
25.9 |
248.2 |
- |
| 2 | 2.7 |
14.0 |
129 |
- |
| 4 | 2.9 |
8.6 |
65 |
640 |
| 8 | 4.6 |
7.1 |
35.5 |
335 |
| 16 | 8.6 |
9.7 |
24 |
173 |
| 28 | 13.9 |
15.2 |
21.4 |
107 |
| 1|cWorkload | 1|c# of | 1|c model single | 1|cobserved single | 1|c|serial |
| 1|c(W) | 1|chistories | 1|c processor execution | 1|c processor execution | 1|c|fraction |
| 1|c | 1|c(Nh) | 1|c time ( |
1|c
time ( |
1|c|(f) |
| 0.01 | 2347 | 3.62 | 3.51 | 0.33 |
| 0.10 | 23843 | 25.8 | 25.9 | 0.045 |
| 1.00 | 238336 | 248.2 | 248.2 | 0.0047 |
| 10.0 | 2383360 | 2472 | - | 0.00047 |
| 100.0 | 23833600 | 24706 | - | 0.000047 |