The basic algorithm that we have employed is the pool of tasks algorithm,
where the MASTER task partitions the workload into tasks, including the
necessary data to perform the simulation. These tasks, denoted the SLAVE tasks,
are dispatched to processors as they become available to process a task. The
partitioning of workload is done within each time step, for this time-dependent
photon transport code, to allow for non-Monte
Carlo computation between time steps, such as to change the material properties
or modify the mesh. Therefore the overall simulation within a time step is
divided into N tasks, where each task has approximately ![]() of the total
workload.
of the total
workload.
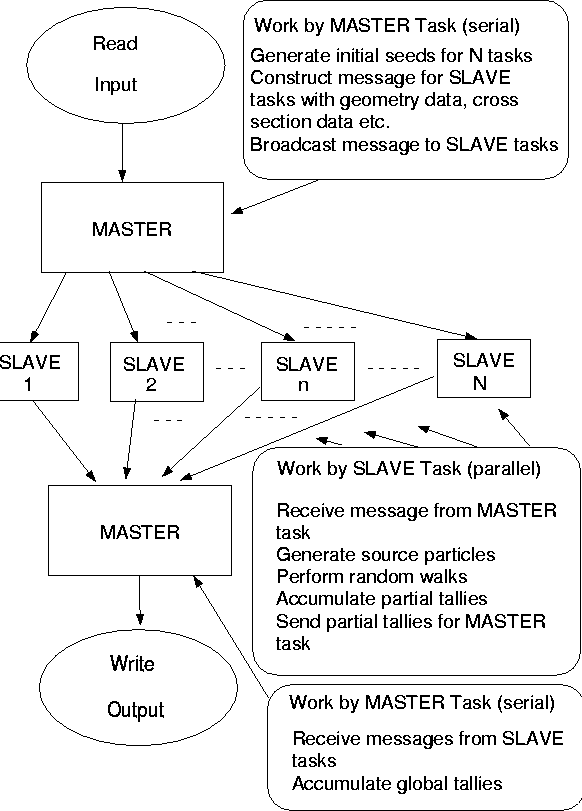
The partitioning of the particles to balance the workload is done statistically among the tasks. The SLAVE task follows the requisite number of particles, accumulating partial tallies and other statistics as needed by the problem, and reports the results back to the MASTER task, which accumulates the partial tallies into overall global tallies. The MASTER task reads the input file, constructs the necessary arrays to describe the geometry and material properties (i.e., cross sections), and transmits these data to the SLAVE tasks. For shared memory parallel processors, such as the Cray YMP, these data are simply stored in the global COMMON, but for a distributed memory parallel processor, this data is sent in a message to each processor to be stored in its local memory. Figure 5.1 illustrates the basic parallel algorithm used in TPHOT.
The overall workload can be divided into four categories: (1) pre-processing work, (2) serial Monte Carlo, (3) parallel Monte Carlo, and (4) post-processing work. The pre-processing work includes reading the input data and preparing geometry and cross section data arrays, while post-processing includes writing the output results. For our analysis, we define the overall simulation time as the sum of the serial Monte Carlo work performed by the MASTER task before and after the random walks, and the parallel Monte Carlo work performed by the SLAVE tasks for the random walk simulations.
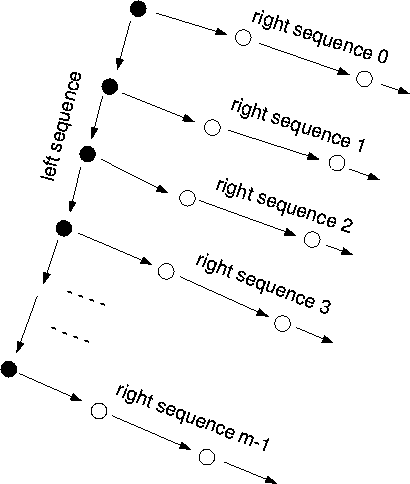
Independent and reproducible sequences of random numbers are generated by the Lehmer [Leh51] tree technique, where the MASTER task generates starting seeds with one generator (the ``left'' generator) and the SLAVE tasks then generate the actual random sequences for their random walks with a second generator (the ``right'' generator). In figure 5.2, the black dots represent the seeds produced by the left generator. The white dots represent random numbers generated by each SLAVE's right generator.