

Technology


Recent Posts
Technology
SDSC Elevates and Ensures Secure Research Infrastructure for DOW Projects
The successful completion of the CMMC framework assessment marks SDSC as a trusted, fully compliant hosting platform for CUI and FCI, opening new...
Education
Technology
Awards
UC San Diego Team Takes Third Place at SC25 Student Cluster Competition in St. Louis
UC San Diego Team Sea++ was awarded third place at this year’s Student Cluster Competition, which took place at the International Conference...
Technology
Science
Cracking the Code of Parkinson’s: How Supercomputers Are Pointing to New Treatments
More than one million Americans live with tremors, slowed movement and speech changes caused by Parkinson’s disease — a degenerative...

Awards
SDSC Receives Honors in 2025 HPCwire Readers’ and Editors’ Choice Awards
The 22nd Annual HPCwire Awards were presented to SDSC leaders in the global HPC community.
Technology
Science
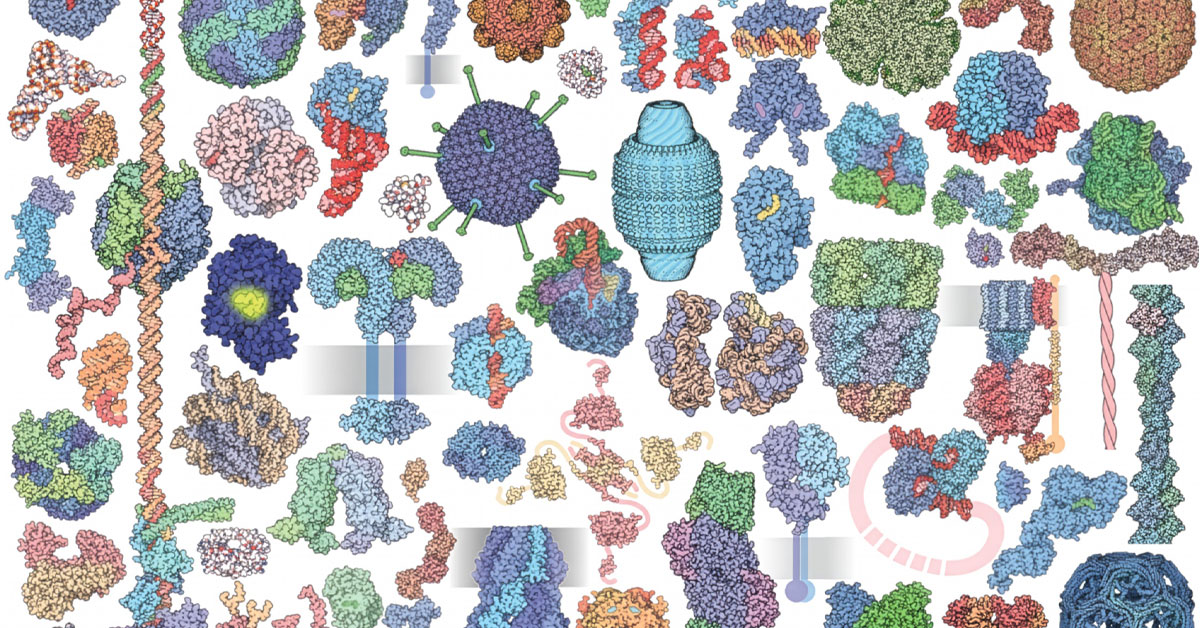
SDSC-housed Protein Data Bank Brings Molecules Up to Size
Molecules craft the very fabric of reality while remaining too small for the human eye to glimpse. But thanks to PDB we can now “see”...

Technology
Education
Science
UC San Diego Team Joins Baltic Partners to Strengthen Ukraine's Groundwater Resilience and Workforce Development
The integration of remote sensing with machine learning allows researchers and students to create better predictions of groundwater storage and flows.

Technology
Education
CAIDA and Internet2 Collaborate for Internet Security Project to Benefit U.S. Research and Education Networks
Scientists share vast amounts of data across institutions and borders, but hidden internet routing problems can quietly send that data off course...

Science
Predictive Science Inc. Advances Dynamic Solar Corona Modeling
Scientists used SDSC's Expanse to create a near-real-time model that accurately depicts the dynamic nature of the sun's outermost...

Science
SDSC’s Expanse Models Illustrate Rare Oxygen Lifelines for Microbes
Oxygen-starved "dead zones" in the ocean seem like they should only support life that can survive without oxygen. Yet scientists have...

Science
Technology
Scientists Use U.S. NSF Supercomputers to Reveal How “Jumping Genes” can Transform Gene Editing Technologies
Researchers uncovered how a bacterial protein can steer genes to specific spots in the genome. Think of it as upgrading genetic scissors into a...

Technology
Science
Awards
UC San Diego Plays Key Role in National Effort to Build a Fusion Research Data Platform
San Diego Supercomputer Center leads UC San Diego’s efforts on this project designed to accelerate development of domestic commercial fusion...

Science
Technology
New AI Tool Predicts Vision Loss Risk in Astronauts — Before Launch
Scientists have carefully studied the effects of space and microgravity on astronauts. One truth is certain: space is brutal on the human body.

Technology
Awards
SDSC's Sherlock Partners with MCNC to Deliver Secure Cloud and Data Services Across North Carolina
Groundbreaking model for cross-country collaboration and networking could serve as technology foundation and potential blueprint for future...

Science
Technology
Discovering the Next Generation of Battery Materials Using Generative AI
As electric vehicles flood global markets and renewable energy storage demands soar, researchers are developing next-gen batteries using...

Science
Computer Modeling Using SDSC Software Illustrates Plastic-Degrading Fungus
Koji mold, has been used to produce foods like soy sauce and miso for thousands of years, but it may also be key to solving a modern problem:...

Science
SDSC Expanse Helps Researchers Better Understand Black Holes in Seyfert Galaxies
Researchers have discovered that black holes don't just devour matter, they actively sculpt the very structure of their host galaxies.

Technology
Science
SDSC Resources Enable Breakthrough in Fiber Network Materials Research
Researchers have achieved a significant breakthrough in understanding materials composed of a network of fibers that could revolutionize medical...

Technology
Science
Wildfire Science & Technology Commons Opens to the Public to Unite and Accelerate Wildfire Solutions
A team of UC San Diego researchers has deployed a groundbreaking new platform to advance science and technology that addresses wildland fire...

Science
Technology
Scientists Use SDSC’s Expanse to Find Better Materials to Turn Seawater into Drinking Water
Four billion people face severe potable water distress due to water pollution and a limited supply of freshwater reserves, one potential solution...

Technology
Education
Seven Global Teams Compete in SDSC’s Third Annual Single-Board Cluster Challenge
Collegiate teams used single-board computers and other similarly simple hardware to create miniature supercomputing clusters and rank them based on...

Education
Rajesh Gupta Appointed Dean of School of Computing, Information and Data Sciences
Rajesh K. Gupta, a distinguished computer scientist and seasoned academic leader, has been named founding dean of the School of Computing,...

Science
SDSC’s Expanse Simulations Unlock Secrets of Blood Vessel Growth
Researchers have made a groundbreaking discovery about how blood flows through the tiniest new blood vessels in our bodies, findings that could...

Education
Mentor Assistance Program Finale Held at San Diego Supercomputer Center
The program enabled more than 50 San Diego high school students to participate in year-round research projects with dedicated mentors throughout...

Technology
SDSC Leader Shares Vision for AI Energy Use Practices at Copenhagen AI Summit
The summit provided government, policymakers, funders, infrastructure and hardware experts a chance to share best practices, lessons learned and...

Technology
Awards
Science
Amarnath Gupta Named SDSC’s Pi Person of the Year
Each year, SDSC recognizes an individual whose research contributions over the years straddle both science and cyberinfrastructure technology. This...