Skip to navigation
Skip to navigation
Site Primary Navigation:
- About SDSC
- Services
- Support
- Research & Development
- Education & Training
- News & Events
Search The Site:
Published 04/01/2011
(This article by SDSC's Jan Zverina, was published March 22, 2011on the TeraGrid website)
The news late last year that China's GPU-rich Tianhe-1A supercomputer was ranked the fastest system in the world focused attention - and a lot of discussion - within the HPC community about the advantages of graphics processing units (GPUs) versus central processing units (CPUs) used in many systems.
While GPUs have for several years primarily been used as fast video game engines to process 3D functions, simulate movement and other mathematically intensive operations that might otherwise strain some CPUs, the newest GPUs are capable of more than making whiz-bang images or movies. Peter Varhol, a contributing editor for the online magazine Desktop Engineering (DE), says GPUs are now capable of performing high-end computations such as those used in engineering applications, in some instances as much as 20 times faster.
However, as Varhol wrote in an article for DE late last year, GPUs don't necessarily trump CPUs every time. In fact, when it comes to engineering-intensive applications, comparing CPUs with GPUs "is like comparing apples with oranges."
"The GPU remains a specialized processor, and its performance in graphics computation belies a host of difficulties to perform true general-purpose computing," Varhol wrote. "The processors themselves require rewriting any software; they have rudimentary programming tools, as well as limits in programming languages and features."
Moreover, most of today's GPU systems are based on a variety of proprietary software systems, while most CPUs used in high-end supercomputers are based on widely accepted industry standards.
"It's expensive to port software in general, and more so when the GPU standard is an evolving target," Varhol said when interviewed for this article. "It's problematic for software vendors to support multiple platforms unless there is a clear market need to do so. So it's almost a chicken and egg problem. It won't become a market need unless we support it, yet it's not cost-effective for us to do so unless the market has already arrived."
Thanks to ongoing support and development by some companies, notably NVIDIA and AMD, software vendors are seeing that it is in their interest to take the plunge, added Varhol. NVIDIA's ( CUDA) parallel computing architecture, for example, has a single industry-standard processor, usually running Windows or Linux, and is based in industry-standard languages such as C and C++, with third-party compilers for Fortran and other standards available.
Plus, NVIDIA and AMD recently announced plans to combine CPUs and GPUs in one chip. This architectural change will eliminate some of the primary architectural bottlenecks that now limit performance .
Within the TeraGrid, several systems are currently running GPUs: the
Lincoln cluster at the National Center for Supercomputing Applications (NCSA) at the University of Illinois at Urbana-Champaign,
Nautilus at the National Institute for Computational Sciences (NICS) in Oak Ridge, Tenn.,
TeraDRE at Purdue University, and the
Longhorn and
Spur systems at the Texas Advanced Computing Center (TACC) at the University of Texas at Austin. There's also the
Keeneland Project
, developed under a partnership that includes the Georgia Institute of Technology (Georgia Tech), the University of Tennessee at Knoxville, and Oak Ridge National Laboratory (ORNL).
"GPUs fit into a small class of new compute technologies that do not get overtaken by the evolutionary progress of CPU technology," says John Towns, director of persistent infrastructure at NCSA and TeraGrid Forum Chair. "They are more comparable to the advent of vector processors, message passing, or even commodity processor technologies applied to HPC, as opposed to technologies such as field programmable gate arrays and the like.
"Such technologies do not establish themselves overnight, however. Each of the successful technologies required a period of time - long in our community - for the development and maturation of the expertise and tools necessary to effectively harness the technology."
More! Better! Faster!
Indeed, GPUs are gaining popularity across many scientific domains: atmospheric modeling, high-energy physics, cosmology, quantum chemistry, molecular dynamics, and even drug design. One common mantra among researchers in just about every science domain is "more, better, faster!" and GPUs are seen as part of the solution to compressing compute times dramatically.
So does this mean that CPUs are becoming obsolete? Not really, because GPUs still require CPUs to access data from disk, or to exchange data between compute nodes in a multi-node cluster. CPUs are excellent for executing serial tasks and every application has those. And as more and more cores are combined on a single chip, CPUs are becoming parallel as well. Plus, GPUs are not right for every application.
"CPUs are designed to handle complexity well, while GPUs are designed to handle concurrency well," says Axel Kohlmeyer, associate director with the Institute for Computational Molecular Science (ICMS) at Temple University in Philadelphia, Pa. Kohlmeyer, a TeraGrid Campus Champion, is working to make GPU codes faster for molecular dynamics applications. "To get good performance from a typical GPU, one needs to write code that parallelizes well across thousands of threads. So the challenge of writing good GPU code is to find sufficient concurrency, then dispatch that work to the GPU while handling other tasks more efficiently on the host processor."
"Essentially, if the effort has been made to port the code to GPUs then the performance improvement over CPU systems can be phenomenal," says Ross Walker, an assistant research professor with the San Diego Supercomputer Center (SDSC) at UC San Diego, another TeraGrid partner. Walker and his team at SDSC have been working with NVIDIA to analyze how GPUs can benefit research in the areas of biomolecules, biofuels, and flu viruses. His research involves high-speed simulations using AMBER, a widely used package of molecular simulation programs.
"GPUs are, for the first time, giving us the increases in capability we have been desperate for since the beginning of the multicore era," says Walker. "I'm confident that we will soon be achieving throughput with GPU-enabled AMBER that is at least an order of magnitude better than we could ever hope to achieve with CPU-based clusters."
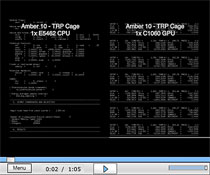
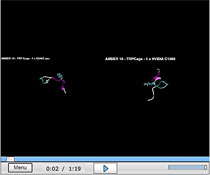
|
Click for an AMBER code output comparison between a
CPU- and GPU-based simulation of Myoglobin, a protein found in muscle fibers.
|
GPUs have come a long way from the days of just being used for video game display graphics. "Special purpose hardware has long been applied in the domain of molecular dynamics simulations with modest success," says Thomas Cheatham, an associate professor at the University of Utah who has been using Lincoln and AMBER to study how biomolecules interact and adapt to their surroundings. "The success was typically modest since CPU power kept improving. This has changed in recent years, largely driven by the demands of video game consumers, such that much more powerful GPUs have been developed that allow sufficient precision and accuracy, speed, and accessible memory for more general scientific applications."
Klaus Schulten, a computational biologist with the University of Illinois' Beckman Institute and director of the university's Theoretical and Computational Biophysics Group, agrees that GPU acceleration is not without its challenges. As computers get larger and computational challenges become more data-intensive, "bottlenecks" are created as machines with GPUs or GPU accelerators speed up computations.
"Our main stumbling block is the communications bottleneck to the GPU device," says Schulten, the largest user within the TeraGrid for GPU research, accessing NCSA's Lincoln. "We have developed software runs that conservatively give us a speedup factor of between 2 and 10, and we believe that we can further improve that. But it puts a burden on the communication path to the GPU, and that becomes problematic."
"One problem is that writing a good GPU code takes time and effort; in many cases, you have to change completely how you think about the physics of the problem that you are working on," says Kohlmeyer, who collaborated on the development of the HOOMD-Blue coarse-grain MD codes and more recently the GPULAMMPS project. "GPUs are in essence a disruptive technology, same as vector processors and Linux cluster computers were. As with any disruptive technology, we need good developers, good programmers- and good scientists."
As Schulten and many other researchers point out, data analysis is becoming a larger part of computational science. "Today we are doing computational studies using bigger and more powerful computers," says Schulten, whose group started and developed NAMD, a molecular dynamics community code to determine how proteins are synthesized and form functional structures. "As as a result our studies have much more data, and analysis becomes more of a serious issue. We now spend easily 50% of our effort on analysis, as compared to the actual computation."
Yet it's the analysis where GPUs come in handy, says Schulten, whose team is also working with NVIDIA. "Here GPUs are very useful, and in some cases we are getting speedups with a factor of over 200."
"GPUs provide an exciting option for high-throughput, highly-parallel computations, especially when co-processing work with the host CPUs," according to Paul Navrátil, a visualization scientist at TACC's Data and Information Analysis division who has been using Longhorn in his research to develop efficient algorithms for large-scale parallel visualization and data analysis (VDA) and innovative design for large-scale VDA systems. "However, to fully harness the processing power of GPUs, there must be sufficient work to keep all elements of the GPU occupied and the work should be regular, or contain few branches. But CPUs are still superior for handling code with random memory accesses and data-driven instruction flow."
To XD and Beyond!
The CPU vs. GPU debate is sure to continue as researchers focus on the development of future computing architectures that are on the path toward exascale systems. DARPA's Ubiquitous High Performance Computing (UHPC) project was launched as a way to explore what the agency calls "extreme scale" computing. Individual teams, led by Intel, Massachusetts Institute of Technology (MIT), NVIDIA, and Sandia National Laboratories have been tasked with creating an innovative, revolutionary new generation of computing systems that overcome the limitations of current approaches.
"GPUs, along with 'manycore' processors, offer a path to future extreme-scale computing through high concurrency, which is the most promising way to hold power consumption at an acceptable level," according to Nick Nystrom, director of strategic computing at the Pittsburgh Supercomputing Center (PSC), and head of the TeraGrid Extreme-Scale Working Group, whose focus is to meet the challenges and opportunities of deploying extreme-scale resources into the TeraGrid to maximize scientific output and user productivity.
"Achieving that level of concurrency often requires revisiting algorithms, which also presents an opportunity to consider applying mixed precision to boost arithmetic speed and decrease communication volume," adds Nystrom. "Given some care with numerical properties, rethinking algorithms in those ways will also benefit performance on manycore and multicore platforms, across which emerging tools are aiming to achieve single-source portability."
"One attraction of GPUs is the fact that one can, on some applications, show great performance per power (flop per watt) ratios," notes Jeffrey Vetter, group leader of the Future Technologies Group in ORNL's Computer Science and Mathematics Division, as well as a joint professor at Georgia Tech and the PI for Keeneland. "As an example, many of the top systems on the Green 500 list are accelerator-based systems."
While GPU-based training is already offered throughout the TeraGrid, GPUs are likely to be a major topic of discussion at TG'11 this July 17-21 in Salt Lake City. But some researchers say more needs to be done to attract, train, and support developers for good GPU code, especially as TeraGrid transitions to the eXtreme Digital (XD) program this year.
"The use of GPUs speeds up a single node considerably, sometimes more than 30 fold," says SDSC's Walker, noting that it is imperative that researchers invest the time and effort to use GPUs effectively. "But if at the same time we don't develop a 30-fold higher bandwidth and 30- fold lower latency interconnect, scaling will always be limited across clusters of GPUs."
"I would hope that the XD program will include more targeted and integrated training and scientific computing awareness outreach than many of the current efforts," says Kohlmeyer, who also favors XD having a diverse pool of GPU-rich resources, primarily because GPU technology is still rapidly changing and some approaches may favor certain scientific disciplines more than others.
"It may be that too many people are distracted by all the hype around GPUs and expect them to do miracles," he adds. "But it is the people who make the difference, the ingenuity with which we use technology that moves us forward, not just to have more technology. After all it doesn't help to get an answer 100 times faster if we don't ask the right questions!"
San Diego Supercomputer Center:
http://www.sdsc.edu
TeraGrid:
https://www.teragrid.org/
National Science Foundation:
http://www.nsf.gov/