Skip to navigation
Skip to navigation
Site Primary Navigation:
- About SDSC
- Services
- Support
- Research & Development
- Education & Training
- News & Events
Search The Site:
Published 09/13/2012
Do you know who Michael Jackson or George Washington was? You most likely do: they are what we call “household names” because these individuals were so ubiquitous. But what about Giuseppe Tartini or John Bachar?
That’s much less likely, unless you are a fan of Italian baroque music or free solo climbing. In that case, you would have heard of Bachar just as likely as Washington. The latter was popular, while the former was not as popular but had interests similar to yours.
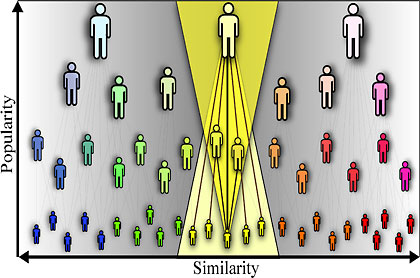
|
Connections in networks optimize trade-offs between popularity and similarity. New nodes in growing networks tend to connect not only to popular existing nodes, but also to similar nodes that may be not so popular. |
A new paper published this week in the science journal Nature by the Cooperative Association for Internet Data Analysis (CAIDA), based at the San Diego Supercomputer Center (SDSC) at the University of California, San Diego, explores the concept of popularity versus similarity, and if one more than the other fuels the growth of a variety of networks, whether it is the Internet, a social network of trust between people, or a biological network.
The researchers, in a study called Popularity Versus Similarity in Growing Networks, show for the first time how networks evolve optimizing a unique trade-off between popularity and similarity. They found that while popularity attracts new connections, similarity is just as attractive.
“Popular nodes in a network, or those that are more connected than others, tend to attract more new connections in growing networks,” said Dmitri Krioukov, co-author of the Nature paper and a research scientist with SDSC’s CAIDA group, which studies the practical and theoretical aspects of the Internet and other large networks. “But similarity between nodes is just as important because it is instrumental in determining precisely how these networks grow. Accounting for these similarities can help us better predict the creation of new links in evolving networks.”
In the paper, Krioukov and his colleagues, which include network analysis experts from academic institutions in Cyprus and Spain, describe a new model that significantly increases the accuracy of network evolution prediction by considering the trade-offs between popularity and similarity. Their model describes large-scale evolution of three kinds of networks: technological (the Internet), social (a network of trust relationships between people), and biological (a metabolic network of the Escherichia coli, typically harmlessly found in the human gastrointestinal tract, though some strains can cause diarrheal diseases.)
The researchers write that the model’s ability to predict links in networks may find applications ranging from predicting protein interactions or terrorist connections to improving recommender and collaborative filtering systems, such as Netflix or Amazon product recommendations.
“On a more general note, if we know the laws describing the dynamics of a complex system, then we not only can predict its behavior, but we may also find ways to better control it,” added Krioukov.
In establishing connections in networks, nodes optimize certain trade-offs between the two dimensions of popularity and similarity, according to the researchers. “These two dimensions can be combined or mapped into a single space, and this mapping allows us to predict the probability of connections in networks with a remarkable accuracy,” said Krioukov. “Not only can we capture all the structural properties of three very different networks, but also their large-scale growth dynamics. In short, these networks evolve almost exactly as our model predicts.”
Many factors contribute to the probability of connections between nodes in real networks. In the Internet, for example, this probability depends on geographic, economic, political, technological, and many other factors, many of which are un-measurable or even unknown.
“The beauty of the new model is that it accounts for all of these factors, and projects them, properly weighted, into a single metric, while allowing us to predict the probability of new links with a high degree of precision,” according to Krioukov.
The other researchers who worked on this project are Fragkiskos Papadopoulos, Department of Electrical Engineering, Computer Engineering and Informatics, Cyprus University of Technology in Cyprus; Maksim Kitsak, CAIDA/SDSC/UC San Diego; M. Ángeles Serrano and Marián Boguñá, Departament de Fisica Fonamental, Univsitat de Barcelona, in Spain.
This research was supported by a variety of grants, including National Science Foundation (NSF) grants CNS-0964236, CNS-1039646, and CNS-0722070; Department of Homeland Security (DHS) grant N66001-08-C-2029; Defense Advanced Research Projects Agency (DARPA) grant HR0011-12-1-0012; and support from Cisco Systems.
International support was provided by a Marie Curie International Reintegration Grant within the 7th European Community Framework Programme; Office of the Ministry of Economy and Competitiveness, Spain (MICINN) projects FIS2010-21781-C02-02 and BFU2010-21847-C02-02; Generalitat de Catalunya grant 2009SGR838; the Ramón y Cajal program of the Spanish Ministry of Science; and the Catalan Institution for Research and Advanced Studies (ICREA) Academia prize 2010, funded by the Generalitat de Catalunya, Spain.
About CAIDA
The Cooperative Association for Internet Data Analysis (CAIDA) is an independent analysis and research group based at the San Diego Supercomputer Center, at UC San Diego. CAIDA is dedicated to investigating both the practical and theoretical aspects of the Internet, with the goal of promoting a robust and scalable global Internet infrastructure.
About SDSC
As an Organized Research Unit of UC San Diego, SDSC is considered a leader in data-intensive computing and all aspects of ‘big data’, which includes data integration, performance modeling, data mining, software development, workflow automation, and more. SDSC supports hundreds of multidisciplinary programs spanning a wide variety of domains, from earth sciences and biology to astrophysics, bioinformatics, and health IT. With its two newest supercomputer systems, Trestles and Gordon, SDSC is a partner in XSEDE (Extreme Science and Engineering Discovery Environment), the most advanced collection of integrated digital resources and services in the world.
For additional comment:
Dmitri Krioukov
858 822-5476 or dima@ucsd.edu
Media Contacts:
Jan Zverina, SDSC Communications
858 534-5111 or jzverina@sdsc.edu
Warren R. Froelich, SDSC Communications
858 822-3622 or froelich@sdsc.edu
San Diego Supercomputer Center: http://www.sdsc.edu/
CAIDA: http://www.caida.org/
UC San Diego: http://www.ucsd.edu/
National Science Foundation: http://www.nsf.gov/